Apr 05 2019

Yesterday, I signed an offer letter from Cloudflare. I’ll be the product manager of Storage, which is the part of the company that’s working on data storage products for the Cloudflare Workers platform. I’ll be starting at the end of the month.
I think a lot of you will say “that makes perfect sense,” but many more will say “wait, what?”. I hope this post will make things a bit more clear.
Before we start, I also want to say that I’ll still be continuing my work on Rust, though obviously in a more limited capacity. I’ll still be working on revisions to The Rust Programming Language, and doing core team work, for example.
Before I worked on Rust, I worked on and with Ruby on Rails. When I got out of the web application game, the hot topic was this new “platform as a service” stuff. I’ve been watching all of the latest changes from afar, and they’ve been quite interesting. I’ve always loved the web, and the people building it. In the last 18 months or so, I’ve also been extremely interested in WebAssembly. Working at Cloudflare is the intersection of four things for me:
- Edge compute
- WebAssembly
- Rust
- Personal and career growth
Edge Compute
There’s sort of been four eras of “how do I web server”:
- Physical servers (“on premise”)
- Infrastructure as a service
- Platform as a service
- Function as a service
A lot of people see the relationship between these things as “what you control” vs “what does the provider control”, but I don’t think that’s quite right. But I’m getting ahead of myself.
Back in the day, if you wanted a web site, you bought a physical server, and you put it in a data center somewhere. I wasn’t around for those days. The point is, you managed everything: the hardware, the software. All of it.
In my days as a startup CTO, my services were deployed to a Virtual Private Server. Instead of owning servers ourselves, we rented a virtual machine, running on someone else’s servers. This is “infrastructure as a service”; I didn’t have to worry about machines, I could just ask for one, and it’d be given to me. I still had to manage the operating system and everything above it.
Fun side note: CloudFab was a Rails application with a big C extension to do data processing that was too much for Ruby. This later informed a lot of my Rust work.
Next up came “platform as a service.” To me, Heroku was the platonic ideal of this era. Now, you didn’t even need to manage servers. You got to worry about your application, and that’s it. Maybe you’d need to set a slider to scale during times of demand.
I’ve been reading a lot about “functions as a service” over the past few years. Instead of deploying an entire application, each endpoint becomes an application, basically. This is where I think the previous thinking about the relationships between these categories of service is a little wrong. The actual underlying trend here is something else: what affordances do I have to scale?
In the on-premise days, if I wanted to add capacity, I’d need to buy new servers, install them, set everything up. There’s a lot of latency there. And if I need to remove capacity, well, I have to sell those servers? The move to infrastructure as a service was significant, because it more clearly separated concerns. Each company didn’t need a data center; a data center provides homogeneous compute. As a user, if I need to scale, I can spin up some more virtual servers much more quickly than I can physical ones. Managing that required a lot of tooling, however.
This was the insight that led to platform as a service: by managing this tooling, you could make it even easier for users to scale. There’s a reason why the slider became the ubiquitous synonym with PaaS. There’s nothing that you could do with PaaS that was impossible with IaaS, but it was much, much easier.
This brings us to Functions as a Service, also known as “serverless.” The reason that this architecture matters is one very similar to previous insights. By breaking your application into multiple functions, they can scale independently. This is one of the dreams of microservice architecture, but there’s a bit of a difference. Microservice architecture focuses on how you build your system, and how you split up components internally. FaaS focuses on how people interact with your system, and splits up the components according to that. This framing is a bit more significant to your ability to scale, because it means that during times of high load, you can scale only the parts under that load. In the same way that IaaS said “let’s not force people to buy servers to scale” and PaaS said “let’s not force people to build out infrastructure to scale”, FaaS says “let’s not force people to scale their help page to scale their shopping cart.”
This brings us to edge compute. Edge compute is a particular kind of FaaS, but an interesting take on it. Here’s the concept: your users are all over the world. Why do their packets need to go to us-east-1 and back? To which you might say, “sure, that’s why we’ve developed our application to work in multiple regions.” That’s the same relationship between IaaS and PaaS. That is, why should you have to worry about making your application be available across multiple regions? You may not be worrying about individual physical servers anymore, but you’re still worrying about data centers. And some FaaS products, like AWS Lambda, can already run easily across multiple regions, and with some setup, go between them. However, Amazon has about 20 total regions.
So how is edge compute different? Well, at some point, various CDN companies realized “wait a minute. We have severs around the world. Why can’t we run compute on them as well?”
Side note: Cloudflare is not really a CDN company, though that’s how I always thought of them. They do a lot more stuff than CDNs.
This is interesting because, well, here’s those 20 Amazon regions:
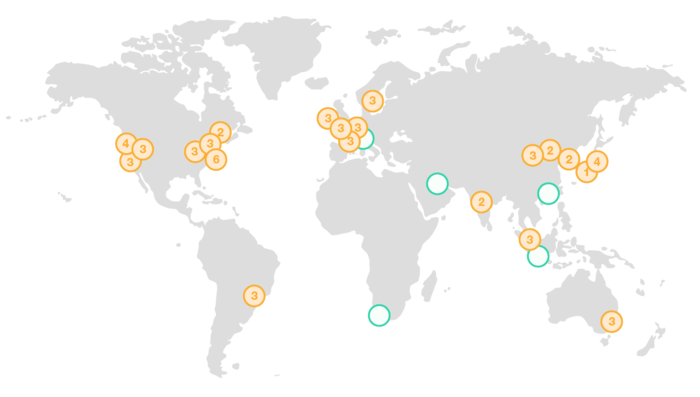
Compare this with Fastly’s network:
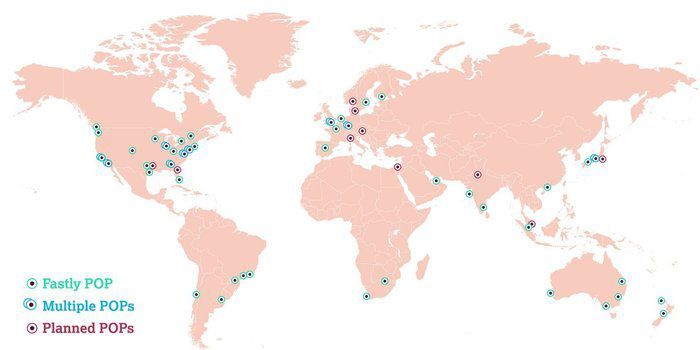
And finally, Cloudflare’s network:
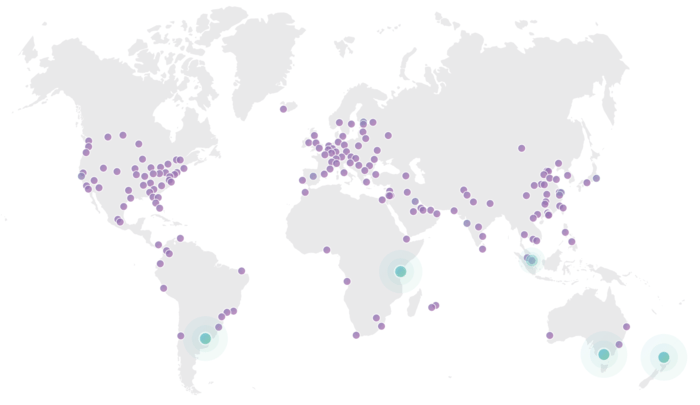
(the page is animated, so those highlighted ones don’t mean anything)
You’re much likely to be physically closer to a Fastly or Cloudflare server than you are an AWS one. And that’s what we mean by “edge compute”, that is, you’re running your code on the edge, rather than in the data center.
Now, I should also mention that there is a form of Lambda called Lambda@Edge that runs off of CloudFront locations, rather than the above map. So that looks like this:
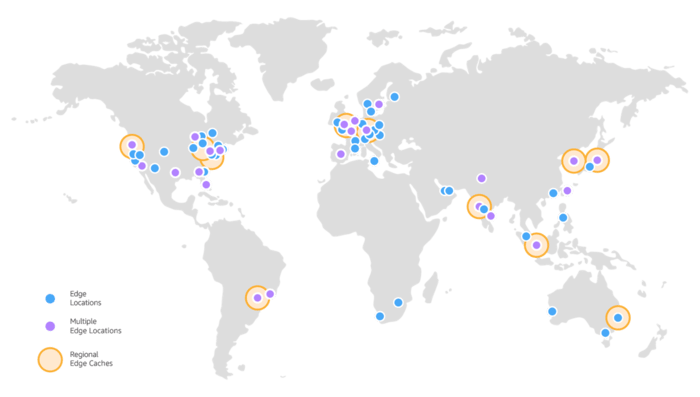
Much better! My point about regions is more applicable to “edge compute” vs more general compute, than saying something about Lambda as a particular product.
CloudFlare Workers don’t require you to think about where your service is deployed: when you upload it, it’s automatically running on all 175 locations, within minutes.
I think this space is interesting and significant. Cloudflare has Workers, and Fastly has Terrarium. Amazon has Lambda@Edge. These are all very interesting platforms for building high performance applications.
My role as part of Storage will be to consider “what does data access and storage look like in this world?” If your code is moved to the edge, but your data is still in a central server, you don’t gain the full benefit of having the code close to the client. There’s a lot of interesting stuff in this space!
WebAssembly
Both ClouldFlare Workers and Fastly’s Terrarium use WebAssembly as a core part of the platform. And that’s significant:
If WASM+WASI existed in 2008, we wouldn’t have needed to created Docker. That’s how important it is. Webassembly on the server is the future of computing. A standardized system interface was the missing link. Let’s hope WASI is up to the task! https://t.co/wnXQg4kwa4 — Solomon Hykes (@solomonstre) March 27, 2019
In order for this stuff to work, you need a runtime for WebAssembly. One interesting thing we’re seeing in this space is sort of two parallel paths emerge: do you want to support JavaScript, or not? Recently, Fastly open sourced Lucet, the WebAssembly runtime that powers Terrarium. It’s an impressive bit of tech. There are others too, like Wasmer and Wasmtime. By focusing purely on WebAssembly, you can build specialized tech, and it can be really, really fast.
However, you can’t compile JavaScript to WebAssembly. You can sort of do it with AssemblyScript, a TypeScript subset the compiles to wasm. But JavaScript is arguably the most popular programming language in the world. I personally believe in JavaScript, even with the rise of WebAssembly. And so Cloudflare is taking a different approach than those projects. Instead of building a wasm-only runtime, they’re building on top of Google’s V8. This means that they can support both WebAssembly and JavaScript in workers. Additionally, by leaning on V8, you can take advantage of all of the excellent engineering resources that Google pours into it, similar to how the Rust compiler gets to take advantage of people working on improving LLVM.
Anyway, the point is, WebAssembly is core to this new edge compute world. And so I’m excited to be in the space. I know people that work at Fastly, wasmer, and Mozilla, and they’re all doing great work. I think there’s space for both approaches, but I’m mostly excited to be there and see how it all turns out.
Oh, one other thing I wanted to say: right now, everything around Workers is closed source. Kudos to Fastly for open-sourcing Lucet. I asked about this in my interview, and Cloudflare is very interested in doing more open source work, and so I’m hoping it doesn’t take us long to catch up in this regard. We’ll see, of course, I haven’t actually started yet. But I think that this stuff needs to be open source, personally.
Rust
You may remember a little story called CloudBleed. In short, Cloudflare had a pretty bad security bug in 2017. This bug happened because of a parser, written in Ragel. Here, I’ll let Cloudflare explain it:
The Ragel code is converted into generated C code which is then compiled. The C code uses, in the classic C manner, pointers to the HTML document being parsed, and Ragel itself gives the user a lot of control of the movement of those pointers. The underlying bug occurs because of a pointer error.
CloudBleed happened due to memory unsafety. When talking to Cloudflare today, it’s pretty clear that this bug was taken extremely seriously, to the point where it created a culture change inside the company itself. These days, it seems to me (I haven’t started yet, mind you) that you have to use a memory safe language by default, and only use a memory unsafe one if you have an extremely good justification. But Cloudflare needs to be able to have a lot of performance, and control latency, in much of their stack.
Enter Rust. Cloudflare started exploring Rust after CloudBleed, and now uses a significant amount of Rust in production. They host the local Rust meetup here in Austin, and sometimes the one in San Francisco. I’m excited to help Cloudflare be successful with Rust, and to use that experience to help improve Rust too.
My understanding is that I’ll be dealing with a bunch of TypeScript and possibly Go as well, which is also pretty cool.
Career growth
Finally, the move to product management. I really enjoy product work, and have had several jobs that were sorta-kinda product jobs. I don’t think that management jobs are inherently better than engineer jobs, of course, but it’s a way for me to grow. My role at Balanced was sorta-kinda-PM-y, and I loved that job.
I don’t have too much more to say about this, just that it’s a bit different, but something I’m really excited to do.
I’m excited for the future
So yeah, that’s my extremely long-winded explanation of what’s going on. I’m not starting until the end of the month, so I’ve got a few weeks to purely enjoy. I’ll still be playing a lot of Celeste and Fortnite, writing blog posts, and working on some Rust open source. But then I get to get back to work. I’m pumped about all of this! New role, building some new tech with tech I already love.